As Google weighs in on ChatGPT, You.com online AI search engine enters the AI chat to replace Google

by Sharon Goldman - venturebeat.com -- One of the biggest topics underlying the hype bonanza since OpenAI’s release of ChatGPT two weeks ago has been: What does this mean for Google search? But it was only on Tuesday evening that Google appeared to finally weigh in on the topic: CNBC reported that employees raised concerns at a recent all-hands meeting that the company was losing its competitive edge in artificial intelligence (AI) given ChatGPT’s quick rise. Building enterprise apps and automating workflows rapidly - but successfully - Low- “Is this a missed opportunity for Google, considering we’ve had Lamda for a while?” read one top-rated question. Alphabet CEO Sundar Pichai and Jeff Dean, the long-time head of Google’s AI division, responded to the question by saying that the company has similar capabilities in its LaMDA model, but that Google has more “reputational risk” in providing wrong information and therefore is moving “more conservatively than a small startup.” ChatGPT, of course, has been heavily criticized for its ability to make up facts while making them sound plausible, and even OpenAI CEO Sam Altman admitted the risks last weekend.
You.com opens up search platform to generative apps
Meanwhile, You.com, the search engine startup founded in 2020 with a moonshot bid to take on Google, announced today that it has opened its search platform to allow external developers and organizations to build their own apps for the search results page. This includes generative AI apps, it says, that have never been seen inside traditional search engines, using generative AI technology that enables users to generate text (YouWrite), code (YouCode), or images (YouImagine) from plain English — all within the search results page. “Whenever someone says Reddit is the new search, or TikTok is the new search, or ChatGPT is the new search, we are usually the first to actually incorporate those features,” Richard Socher, cofounder and CEO of You.com, told VentureBeat. “ChatGPT is coming from large language models — we were actually the first search engine that uses large language models to generate code insights or to generate natural language or new images inside the search results.”
Next step in effort to offer Google search alternative

سجعان قزي
@AzziSejean
ليست البطريركيّةُ المارونيّةُ غُصنًا يَتمايل يُمنةً ويُسرَة، ولا أُذُنًا تَتأثّر بكلِّ هَـمْسة. لذلك لا داعٍ لأنْ يَقلَقَ البعضُ ويَهلَعَ كلما طَلعت هذه الشخصيةُ أو تلك درجَ بكركي. المهِمُّ أن نَرصُدَ خُطواتِها لدى خروجِها ونُزولِـها الدَرَج. إنَّ طائفةً يرقى عمرُها إلى القرنِ الخامسِ، وبطريركيّةً يَرجِعُ تأسيسُها إلى القرنِ السابعِ ما عادَتا غُصنًا بل جِذْعًا مُتجذِّرًا في الأرضِ والتاريخِ يُواجهُ العواصفَ ويَرُدّها على أعقابِها وإلى مصادرِها.
وحين يَستقبل غِبطةُ البطريركِ الكاردينال بشارة الراعي زوّارًا من جميعِ الاتّجاهاتِ ويُصغي إليهم بانتباه، في أوّلِ الأسبوعِ أو في وسَطِه أو في آخِرِه، لا يَظُنَّنَّ أحدٌ منهم أنه كَسَبَ البطريركَ إلى جانبِه و"راحَت" على الآخَرين. الإصغاءُ من بابِ اللياقةِ لا من بابِ الاقتناع. لكنْ، طبيعيٌّ أن يَتوقّفَ غِبطَتُه عند أي فكرةٍ جيدةٍ ونزيهةٍ تُبدَى أمامَه بغضّ النظرِ عن صاحبها، فالمعرفةُ نَبعٌ يَجِفُّ من دون سَقْيٍ دوْريّ. يتركهم في غموضٍ والتباسٍ وقلقٍ، إلى أنْ يُطِلَّ عليهم في عِظتِه كلَّ أحدٍ فيُدرِكُ الجميعُ حينئذ أنَّ ما بُني على صخرٍ لا يَهُــزّه زوّارٌ أو مُتغيِّبون.
وخلافًا لِما يَتوَهّمُ البعضُ، غِبطتُه يَعرِف مَقصِدَ كلِّ زائرٍ والغرضَ، ويَملِكُ القدرةَ على التمييزِ بين الحقِّ والباطلِ، والمناسِب والنافر، وبين صاحبِ الحاجةِ وصاحبِ الحُجَّة. وهذا التمييزُ يَسري على كلِّ زائرٍ أكان رئيسًا للجُمهوريّةِ أم مواطِنًا عاديّا أو مرشَّحًا للرئاسةِ زادَ طموحُه عن مؤهَّلاتِه بالولادَة. لكن، ما يُزعجُ غِبطتَه أنْ يَخرجَ زوّارٌ بعدَ لقائه ويُصرِّحوا خِلافَ ما جرى من حديثٍ ويَتركوا الانطباعَ بأنَّ غِبطتَه أيّدَهم في مواقِفِهم. وهنا تبدأ المبارزاتُ السياسيّةُ والسجالاتُ الإعلاميّةُ الفاقدةُ الصدقيّةِ.
جميعُ المكوّناتِ السياسيّةِ المؤمِنةِ بلبنان، مسيحيّةٍ ومُسلمةٍ، تَكُنُّ للبطريركيةِ المارونيّةِ الاحترامَ، وتَلقى لدى سيّدِها مَلاذَ الموقِفِ الوطنيِّ المبدئيِّ والمنفتِح. وحتى حين تُدافعُ البطريركيّةُ عن حقوقِ المسيحيّين فَعَن حقوقِ جميعِ اللبنانيّين تُدافع. وتَفعل ذلك من المنطلقات التالية: 1) دورهُا التأسيسيُّ الخاصُّ في قيامِ دولةِ لبنان الذي يَفرِضُ عليها واجبَ احتضانِ المكوّناتِ الأخرى وتَفهُّمَ شكواهُم. 2) إعطاؤُها الأولويّةَ لمفهومِ الميثاقِ الوطنيِّ الذي يَقتضي اعتبارَ مصالحِ الطوائفِ الأخرى بمثابةِ مصالحِ الطائفةِ المارونيّة. 3) انتشارُها الواسعُ في سائرِ دولِ العالم ما يُعطيها القدرةَ على أن تَطرحَ قضيّةَ كلِّ اللبنانيّين على مراكز القرار (هذا إذا فَعّلَت الكنيسةُ طاقاتِها وجَدَّدت طاقمَها).

by time.com -- BY NIK POPLI -- Ammaar Reshi was playing around with ChatGPT, an AI-powered chatbot from OpenAI when he started thinking about the ways artificial intelligence could be used to make a simple children’s book to give to his friends. Just a couple of days later, he published a 12-page picture book, printed it, and started selling it on Amazon without ever picking up a pen and paper.
Reshi, a product design manager from the San Francisco Bay Area, gathered illustrations from Midjourney, a text-to-image AI tool that launched this summer, and took story elements from a conversation he had with the AI-powered ChatGPT about a young girl named Alice. “Anyone can use these tools,” Reshi tells TIME. “It’s easily and readily accessible, and it’s not hard to use either.” The feat, which Reshi publicized in a viral Twitter thread, is a testament to the incredible advances in AI-powered tools like ChatGPT—which took the internet by storm two weeks ago with its uncanny ability to mimic human thought and writing. But the book, Alice and Sparkle, also renewed a fierce debate about the ethics of AI-generated art. Many argued that the technology preys on artists and other creatives—using their hard work as source material, while raising the specter of replacing them.
His experiment creating an AI-generated book in just one weekend shows that artificial intelligence might be able to accomplish tasks faster and more efficiently than any human person can—sort of. The book was far from perfect. The AI-generated illustrations had a number of issues: some fingers looked like claws, objects were floating, and the shadowing was off in some areas. Normally, illustrations in children’s books go through several rounds of revisions—but that’s not always possible with AI-generated artwork on Midjourney, where users type a series of words and the bot spits back an image seconds later. Alice and Sparkle follows a young girl who builds her own artificial intelligence robot that becomes self aware and capable of making its own decisions. Reshi has sold about 70 copies through Amazon since Dec. 4, earning royalties of less than $200. He plans to donate additional copies to his local library. Reshi’s quixotic project drew praise from many users for its ingenuity. But many artists also strongly criticized both his process and the product. To his critics, the speed and ease with which Reshi created Alice and Sparkle exemplifies the ethical concerns of AI-generated art. Artificial intelligence systems like Midjourney are trained using datasets of millions of images that exist across the Internet, then teaching algorithms to recognize patterns in those images and generate new ones. That means any artist who uploads their work online could be feeding the algorithm without their consent. Many claim this amounts to a high-tech form of plagiarism that could seriously harm human artists in the near future. Reshi’s original tweet promoting his book received more than 6 million impressions and 1,300 replies, many of which came from book illustrators claiming artists should be paid or credited if their work is used by AI.
by venturebeat.com -- Ben Dickson -- For decades, we have personified our devices and applications with verbs such as “thinks,” “knows” and “believes.” And in most cases, such anthropomorphic descriptions are harmless. But we’re entering an era in which we must be careful about how we talk about software, artificial intelligence (AI) and, especially, large language models (LLMs), which have become impressively advanced at mimicking human behavior while being fundamentally different from the human mind. It is a serious mistake to unreflectively apply to artificial intelligence systems the same intuitions that we deploy in our dealings with each other, warns Murray Shanahan, professor of Cognitive Robotics at Imperial College London and a research scientist at DeepMind, in a new paper titled, “Talking About Large Language Models.” And to make the best use of the remarkable capabilities AI systems possess, we must be conscious of how they work and avoid imputing to them capacities they lack.
Humans vs. LLMs
“It’s astonishing how human-like LLM-based systems can be, and they are getting better fast. After interacting with them for a while, it’s all too easy to start thinking of them as entities with minds like our own,” Shanahan told VentureBeat. “But they are really rather an alien form of intelligence, and we don’t fully understand them yet. So we need to be circumspect when incorporating them into human affairs.” Human language use is an aspect of collective behavior. We acquire language through our interactions with our community and the world we share with them. “As an infant, your parents and carers offered a running commentary in natural language while pointing at things, putting things in your hands or taking them away, moving things within your field of view, playing with things together, and so on,” Shanahan said. “LLMs are trained in a very different way, without ever inhabiting our world.” LLMs are mathematical models that represent the statistical distribution of tokens in a corpus of human-generated text (tokens can be words, parts of words, characters or punctuations). They generate text in response to a prompt or question, but not in the same way that a human would do. Shanahan simplifies the interaction with an LLM as such: “Here’s a fragment of text. Tell me how this fragment might go on. According to your model of the statistics of human language, what words are likely to come next?”

by science.org -- Instagram users don’t mind teaching lessons to bots If someone showed you a photo of a crocodile and asked whether it was a bird, you might laugh—and then, if you were patient and kind, help them identify the animal. Such real-world, and sometimes dumb, interactions may be key to helping artificial intelligence learn, according to a new study in which the strategy dramatically improved an AI’s accuracy at interpreting novel images. The approach could help AI researchers more quickly design programs that do everything from diagnose disease to direct robots or other devices around homes on their own. “It’s supercool work,” says Natasha Jaques, a computer scientist at Google who studies machine learning but who was not involved with the research.
Many AI systems become smarter by relying on a brute-force method called machine learning: They find patterns in data to, say, figure out what a chair looks like after analyzing thousands of pictures of furniture. But even huge data sets have gaps. Sure, that object in an image is labeled a chair—but what is it made of? And can you sit on it? To help AIs expand their understanding of the world, researchers are now trying to develop a way for computer programs to both locate gaps in their knowledge and figure out how to ask strangers to fill them—a bit like a child asks a parent why the sky is blue. The ultimate aim in the new study was an AI that could correctly answer a variety of questions about images it has not seen before. Previous work on “active learning,” in which AI assesses its own ignorance and requests more information, has often required researchers to pay online workers to provide such information. That approach doesn’t scale.

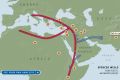


Population Movements to Keserwan - The Khazens and The Maans
ما جاء عن الثورة في المقاطعة الكسروانية
ثورة أهالي كسروان على المشايخ الخوازنة وأسبابها
Origins of the "Prince of Maronite" Title
Growing diversity: the Khazin sheiks and the clergy in the first decades of the 18th century
Historical Members:
Barbar Beik El Khazen [English]
Patriach Toubia Kaiss El Khazen(Biography & Life Part1 Part2) (Arabic)
Patriach Youssef Dargham El Khazen (Cont'd)
Cheikh Bishara Jafal El Khazen
Patriarch Youssef Raji El Khazen
The Martyrs Cheikh Philippe & Cheikh Farid El Khazen
Cheikh Nawfal El Khazen (Consul De France)
Cheikh Hossun El Khazen (Consul De France)
Cheikh Abou-Nawfal El Khazen (Consul De France)
Cheikh Francis Abee Nader & his son Yousef
Cheikh Abou-Kanso El Khazen (Consul De France)
Cheikh Abou Nader El Khazen
Cheikh Chafic El Khazen
Cheikh Keserwan El Khazen
Cheikh Serhal El Khazen [English]
Cheikh Rafiq El Khazen [English]
Cheikh Hanna El Khazen
Cheikha Arzi El Khazen
Marie El Khazen